AI生成物の利益還元モデル(前編)

※本コラムは、執筆者の私見によるものであり、所属団体その他の見解を代表するものではありません。また、執筆者の過去学会発表・論文・書籍・ブログなどですでに発表済みの内容を再編集しています。
IP Scopeの狙いは、特許をはじめとする知財に関する情報を分析することによって、技術動向や今後の予想、企業の技術戦略を見つけ出すことにある。ビッグデータ時代である現在は、データ分析によって新たな知見を見出し、それを企業の戦略やオペレーションに活かすことが重要になってきている。
一方、特許という技術分析のみで企業の戦略やオペレーションを立案することは危険である。「ルール形成」という分野があるように、現状の問題点を把握して、「標準化」なども組み合わせて新しい「ルール」を作っていくことをリードする必要性も時には生ずる。
このコラムでは、NBIL-5による環境やテクノロジーの最新状況分析を踏まえ、それぞれの分野の動向や課題を明らかにしていく。
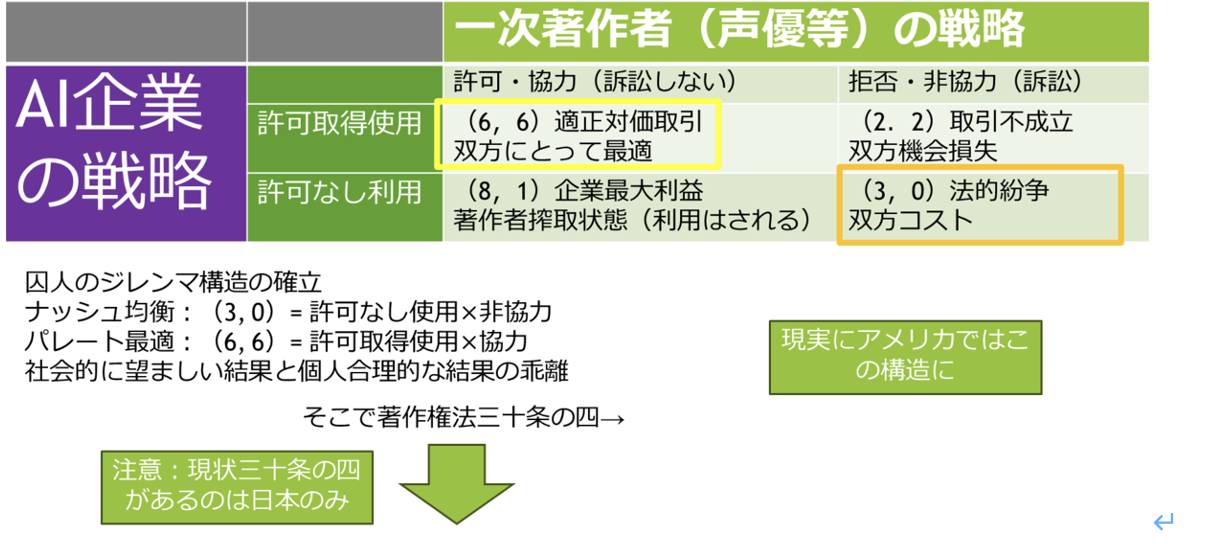
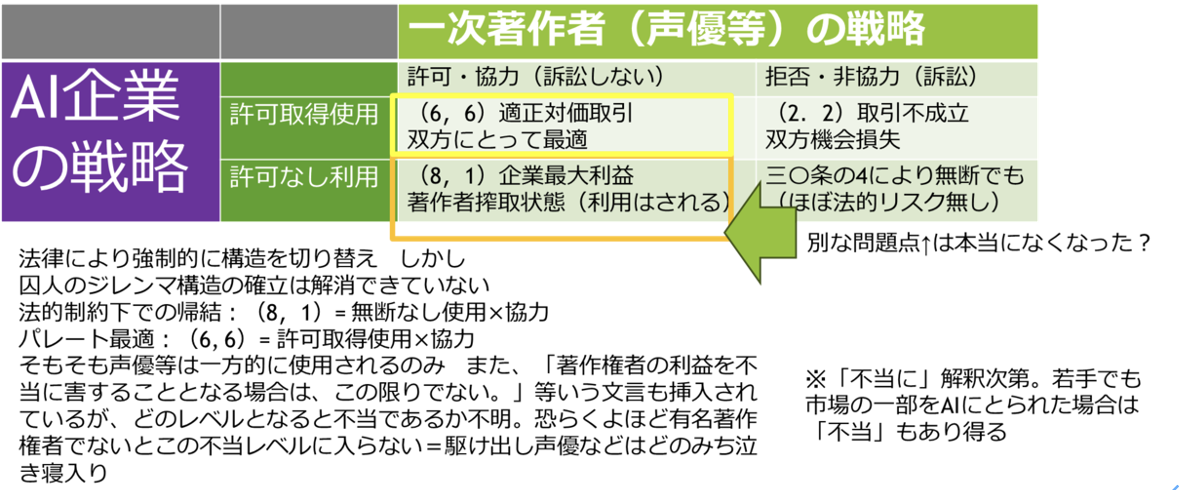
まずは、以前より本問題に関して主張していたことからは予想通りだが、AIの学習データは裁判多発だ。
「ディズニーなど、米AI新興を著作権侵害で訴え 映画大手で初」
https://www.nikkei.com/article/DGXZQOGN11DXI0R10C25A6000000/「BBC、米AI新興に法的措置警告 自社コンテンツの利用巡り」
https://www.nikkei.com/article/DGXZQOGR2096W0Q5A620C2000000/?msockid=357ee500df386908312ef766de426860
その反面還元モデルも動きつつある
「AI学習の対価還元プログラムがスタート!あらたな収益の仕組みでより創作を続けやすく」note公式, 2025年6月17日 https://note.com/info/n/n49bbcbdefe1a
さて、以前から様々書いているが、もう一度おさらいをしたい。
生成AIの利益還元モデルの必要性
▶ 問題の背景:生成AI市場は2030年までに1,100億ドル以上の規模への成長が予測される一方で、声優や俳優などの一次著作物の音声・映像データが無断でAI学習に使用され、本人への対価還元がなされなければ深刻な問題が発生しています。現状では、AI生成物の帰属が不明確で、元データ提供者への適切な還元システムが存在しません。その為、声優や俳優より反対の声が上がっています。
逆に言えばこれは社会課題ニーズともいえます。
※根拠
▪️https://www.grandviewresearch.com/industry-analysis/generative-ai-market-report
「2030年までに1,093億7000万ドルに達すると予測」
▪️https://www.statista.com/outlook/tmo/artificial-intelligence/generative-ai/worldwide
「2031年までに市場規模は4,420億、7000万米ドルと予測」
▪️https://www.abiresearch.com/news-resources/chart-data/report-artificial-intelligence-market-size-global
「2030年には4,670億米ドルに達すると予測」
▪️https://wired.jp/article/hollywood-sag-strike-artificial-intelligence/
「ハリウッドのAI使用反対ストライキ」
▪️https://www.nippairen.com/about/2025.html
わが国においても日本俳優連合をはじめ関連団体が精力的に意見を主張中。